機械学習とは?種類や仕組み・活用例を簡単にわかりやすく解説

AIの進化が私たちの生活やビジネスに大きな変革をもたらしているいま、その中核を担う技術が「機械学習」です。しかし、機械学習とは具体的にどのような技術で、どんなことができるのでしょうか。
この記事では、機械学習についてくわしく知りたい方に向けて、基本的な概念から実践的な応用例まで、わかりやすく解説していきます。この記事を読むことで、以下のような理解が得られます。
- 機械学習の基本概念と重要性
- 主要な学習方法の種類と特徴
- 実際のビジネスでの活用事例
- 機械学習を導入する際の注意点
それでは、データ駆動型の未来を支える機械学習について、一緒に学んでいきましょう。
- 機械学習とは|基本概念
- 機械学習の定義と特徴
- AIと機械学習の関係性
- 機械学習の重要性と応用分野
- 機械学習の仕組みと基本原理
- 機械学習のプロセスと流れ
- 学習データの役割と重要性
- 機械学習モデルの概念
- 機械学習の種類(主要な学習方法)
- 教師あり学習の特徴
- 教師なし学習の特徴
- 強化学習の特徴
- 機械学習の代表的なアルゴリズムとモデル
- ニューラルネットワークの基本構造
- 決定木とランダムフォレストの特徴
- サポートベクターマシン(SVM)の原理
- 機械学習の実践的な応用と活用事例
- 画像認識と自然言語処理
- 予測分析と異常検知
- 機械学習を活用したイノベーションの創出
- 機械学習の導入における課題と対策
- 導入前段階での目的の明確化
- セキュリティ対策の徹底
- 必要なデータの収集
- データ整理の徹底
- 従業員の研修・資格取得支援の実施
- まとめ
- ディープラーニングで活用するならGPUクラウドサービスがおすすめ
機械学習とは|基本概念

機械学習とは、コンピュータ(機械)が大量のデータを分析し、パターンやルールを自動で学習する技術です。従来のプログラミングでは、人間があらかじめすべての動作をルールとして記述する必要がありましたが、機械学習では、データから自動的にルールを見出し、新しいデータに対しても適切な判断や予測をおこなうことができます。
このアプローチにより、以下のような利点が生まれます。
- 複雑なパターンの認識が可能
- 適切なデータ量と質があれば精度が向上
- 人手では処理しきれない大量のデータを活用可能
- 経験と勘に頼らないデータドリブンな意思決定
機械学習の定義と特徴
機械学習は、コンピュータが大量のデータから自律的にパターンを学習し、そこから得られた知見をもとに予測や判断をおこなう技術です。人間が明示的にルールを設定するのではなく、データから自動的に法則性を見出すことが最大の特徴です。この技術には、以下のような主要な特徴があります。
| データ駆動型アプローチ | データの量と質が学習の成否を左右 適切な新規データと再学習により精度向上が可能 データの特性に応じて柔軟に学習方法を変更可能 |
| パターン認識能力 | 複雑なデータのなかから規則性を自動的に発見 人間には気づきにくい相関関係の抽出が可能 多次元データの分析や非線形な関係性の把握が得意 |
| 自動化による効率化 | 反復的なタスクを自動的に処理 リアルタイムでの判断・予測が可能 大規模データの処理を効率的に実行 |
| 適応性の高さ | 環境やデータの変化に対して柔軟に対応 新しい事例からの継続的な学習が可能 モデルの更新による性能改善が容易 |
従来のプログラミングと機械学習では、アプローチが大きく異なります。従来のプログラミングでは、プログラマーが「もしAならばBを実行する」というように、すべての処理ルールを明示的に記述する必要がありました。これに対して機械学習では、データを与えることでシステムが自ら適切なルールを見出していきます。
たとえば、スパムメールの判定を例に考えてみましょう。従来のプログラミングでは、「特定のキーワードが含まれている」「送信元アドレスが不審である」といった判定ルールを人間が一つひとつ設定する必要がありました。一方、機械学習では大量のメールデータを与えることで、システムが自動的にスパムメールの特徴を学習し、新しいタイプのスパムメールにも柔軟に対応できるようになります。
このように機械学習は、人間が事前に想定できないような複雑なパターンの発見や、データ量の増加に応じた継続的な性能向上を可能にします。とくに近年のビッグデータ時代において、その重要性はますます高まっています。
AIと機械学習の関係性
人工知能(AI)と機械学習の関係について正しく理解することは、これらの技術を効果的に活用するうえで重要です。両者は密接に関連していますが、同じものではありません。それぞれの位置づけと関係性について見ていきましょう。
人工知能(AI)とは、人間の知的能力をコンピュータで実現しようとする技術の総称です。具体的には、学習能力、推論能力、認識能力、自然言語の理解など、人間の知的な振る舞いを模倣し、実現することを目指しています。これは非常に広い概念で、機械学習はその実現手段の1つとして位置づけられます。
AIのなかでの機械学習の位置づけは以下のようになっています。
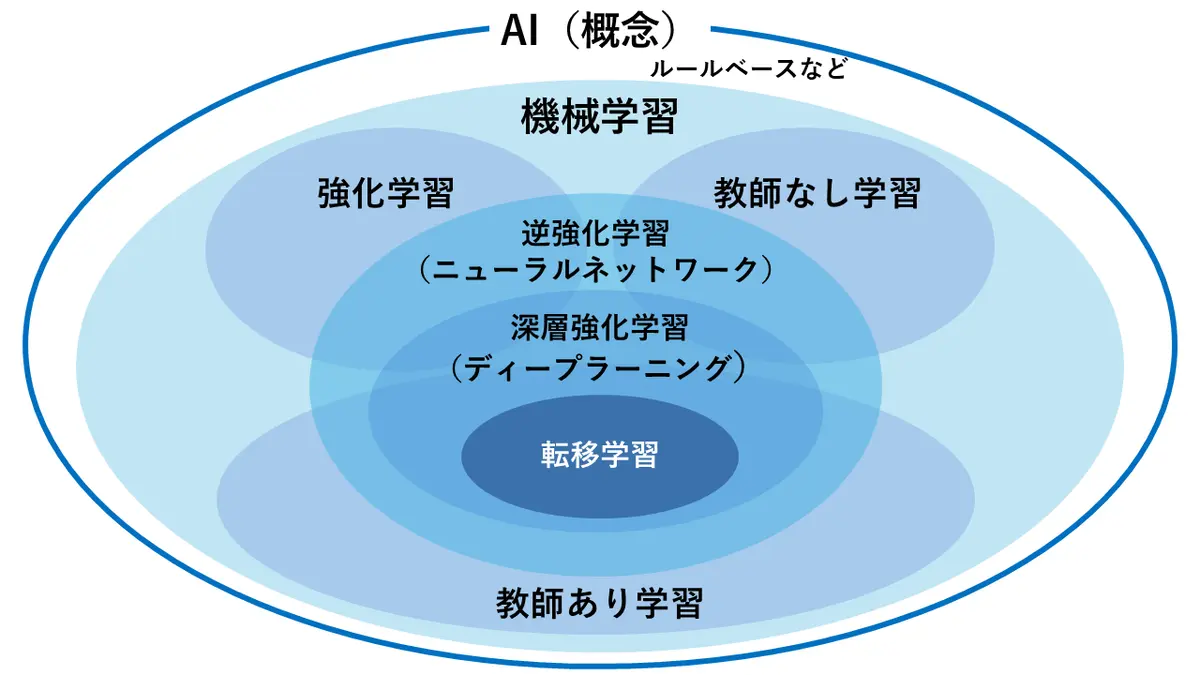
- AI(人工知能)
- もっとも広い概念として知的な振る舞いを実現する技術全般を包含
- 機械学習以外にも、エキスパートシステムや自然言語処理なども含む
- 人間の知能を模倣するためのさまざまなアプローチを統合
- 機械学習
- AIの実現手段としてもっとも重要な要素技術の一つ
- データからパターンを学習し、予測や判断をおこなう
- ディープラーニングを含むさまざまな学習手法を包含
- ディープラーニング
- 機械学習の一手法として位置づけられる
- 人間の脳の神経回路を模した深層学習を実現
- とくに画像認識や自然言語処理で高い性能を発揮
この関係性を理解することで、それぞれの技術の特徴と限界を把握し、適切な活用が可能になります。たとえば、単純なデータ分析であれば従来の機械学習手法で十分かもしれませんが、画像認識や自然言語処理といった複雑なタスクではディープラーニングが適している、といった判断ができるようになります。
これらの技術は互いに補完し合いながら発展を続けており、とくに近年はディープラーニングの進歩により、AIの実用化が大きく前進しています。ただし、それぞれの技術には得意・不得意な領域があるため、課題に応じて適切な技術を選択することが重要です。
機械学習とディープラーニング(深層学習)の違い
機械学習とディープラーニング(深層学習)は、どちらもAIを実現するための技術ですが、そのアプローチと特徴には大きな違いがあります。おもな違いは以下の4点に集約されます。
| 機械学習 | ディープラーニング | |
|---|---|---|
| 特徴量の扱い方 | 人間が特徴量(データの特徴を表す要素)を設計 | 特徴量も自動的に学習・抽出 |
| 必要なデータ量と計算リソース | 比較的少ないデータでも学習可能、一般的なコンピュータで実行可能 | 大量のデータが必要、高性能なGPUなどの計算リソースが必要 |
| 精度と柔軟性 | 人間が設計した特徴量に依存、比較的シンプルな問題に適している | 複雑なパターンの認識が可能、高い精度を実現 |
| 適している領域 | 構造化データ(数値データ、カテゴリデータなど)の分析 | 非構造化データ(画像、音声、自然言語など)の処理 |
たとえば、画像認識を例に考えてみましょう。
- 機械学習の場合:人間が「エッジの数」「色の分布」などの特徴を指定して学習
- ディープラーニングの場合:画像から自動的に重要な特徴を抽出して学習
ただし、ディープラーニングが常に最適な選択というわけではありません。以下のような場合は、従来の機械学習手法のほうが適している可能性があります。
- データ量が限られている場合
- 結果の解釈可能性が重要な場合
- リソースやコストに制約がある場合
- シンプルな問題解決で十分な場合
このように、機械学習とディープラーニングはそれぞれに特徴があり、扱う問題や状況に応じて適切な手法を選択することが重要です。両者の特徴を理解し、課題に応じて使い分けることで、より効果的なAIソリューションを実現することができます。
なお、ディープラーニングについてよりくわしく知りたい方は、以下の記事をご覧ください。
ディープラーニングとは? 仕組みや企業の活用例・導入方法をわかりやすく解説
>>記事を見る
機械学習の重要性と応用分野
ビッグデータ時代の到来により、企業や組織が日々大量のデータを生成・収集できるようになりました。しかし、この膨大なデータから価値を見出すには、人間の処理能力では限界があります。ここで機械学習の重要性が浮かび上がってきます。機械学習は、増加し続けるデータから自動的にパターンを見出し、意思決定や予測に活用できる強力なツールです。
機械学習が活用されている主要な産業分野には、以下のようなものがあります。
| 産業分野 | 現在の応用例 | 将来の可能性 | 期待される効果 |
|---|---|---|---|
| 医療・ヘルスケア | AI画像診断による早期がん発見支援 | 個人のゲノム情報と生活習慣データを組み合わせた予防医療の実現 | 診断精度の向上と医療コストの削減 |
| 金融 | リアルタイムの不正取引検知システム | 個人の経済活動パターンにもとづくカスタマイズされた資産運用提案 | リスク管理の強化と新しい金融サービスの創出 |
| 製造業 | センサーデータによる予知保全システム | 完全自動化された生産ラインの実現と品質管理の自動最適化 | 生産効率の向上とコスト削減 |
| 小売・流通 | 購買履歴にもとづく需要予測システム | リアルタイムの在庫最適化と配送ルート自動調整 | 在庫ロスの削減と顧客満足度の向上 |
| 農業 | ドローンと画像認識による作物の生育状態モニタリング | 気象データと土壌センサーを組み合わせた収穫量の最適化 | 農業の効率化と持続可能性の向上 |
| 教育 | 学習進捗に応じた個別カリキュラムの提供 | 生徒の理解度と学習スタイルに完全適応する教育システム | 教育の個別最適化と学習効果の向上 |
機械学習が社会や産業にもたらす潜在的な影響は、以下の3つの観点から考えることができます。
- 生産性の革新
- 業務の自動化による効率化
- 人的エラーの削減
- リソースの最適配分
- 新しい価値の創造
- パーソナライズされたサービスの実現
- データにもとづく新規ビジネスモデルの創出
- 既存サービスの付加価値向上
- 社会課題の解決
- 環境負荷の軽減
- 高齢化社会への対応
- 地域格差の解消
このように機械学習は、単なる業務効率化のツールを超えて、社会や産業の構造そのものを変革する可能性を秘めています。とくに、複数の技術やデータを組み合わせることで、これまでにない革新的なソリューションを生み出すことができます。
ただし、これらの可能性を実現するためには、適切なデータの収集・管理体制の構築や、プライバシーへの配慮、倫理的な考慮など、さまざまな課題にも取り組む必要があります。機械学習の発展とともに、これらの課題に対する解決策を見出していくことも重要となっています。
機械学習の仕組みと基本原理

機械学習システムを構築する際には、データの収集から実際の運用まで、複数の重要なステップが存在します。それぞれのステップには固有の課題があり、適切に対処することで精度の高いモデルを実現できます。以下では、機械学習の基本的な仕組みとプロセスについてくわしく見ていきましょう。
機械学習のプロセスと流れ
機械学習プロジェクトを成功させるためには、適切な手順と各段階での綿密な検討が必要です。ここでは、機械学習の一般的なプロセスとそれぞれの段階で注意すべきポイントについて説明します。
| 注意点 | |
|---|---|
| ①データ収集 | ・目的に合った質の高いデータを十分な量収集する ・データの信頼性と代表性を確認する ・個人情報の保護やプライバシーに配慮する |
| ②データの前処理 | ・欠損値の補完や外れ値の処理をおこなう ・データの正規化やスケーリングを実施する ・必要に応じて特徴量の選択や生成をおこなう ※この段階での丁寧な作業が後の精度を大きく左右する |
| ③モデルの選択 | ・問題の種類に適したアルゴリズムを選ぶ ・利用可能な計算リソースを考慮する ※結果の解釈可能性も重要な選択基準となる |
| ④モデルの学習 | ・適切なハイパーパラメータを設定する ・学習の進捗を常にモニタリングする ・必要に応じて交差検証を実施する ・過学習の兆候がないか注意深く観察する |
| ⑤モデルの評価 | ・テストデータを使用して性能を検証する ・複数の評価指標を用いて総合的に判断する ・エラーの傾向を分析し、改善点を特定する |
| ⑥デプロイメント | ・本番環境への展開を慎重におこなう ・継続的なパフォーマンスモニタリングを実施する ・定期的なモデルの更新計画を立てる |
これらのステップは、必要に応じて何度も繰り返し実施することがあります。また、各段階で問題が見つかった場合は、前のステップに戻って修正をおこなうことも重要です。機械学習プロジェクトは、この一連のプロセスを通じて、徐々に精度と信頼性を高めていきます。
学習データの役割と重要性
機械学習において、データは成功の鍵を握るもっとも重要な要素です。いくら優れたアルゴリズムを使用しても、データの質が低ければよい結果は得られません。
機械学習における「データ」とは、モデルが学習し予測をおこなうための情報のことです。データは大きく以下の3種類に分類されます。
| 学習データ(訓練データ) | ・モデルの学習に直接使用するデータ ・全体の60~80%%程度を使用するのが一般的 ・パターンやルールの抽出に使用 |
| 検証データ | ・モデルの調整と性能評価に使用 ・全体の10~20%程度を使用 ・ハイパーパラメータの最適化に活用 |
| テストデータ | ・最終的な性能評価に使用 ・全体の10~20%程度を使用 ・学習には一切使用せず、純粋な評価用として確保 |
データの質と量は、以下のようにモデルの性能に直接的な影響を与えます。
- データの質が高いほど、モデルの予測精度が向上
- 十分なデータ量がないと、過学習のリスクが増加
- バイアスのないデータ収集が重要
- ノイズの少ないクリーンなデータが望ましい
また、データ前処理は、生のデータを機械学習に適した形に変換する重要な工程です。おもな手法には以下があります。
| データクレンジング | ・欠損値の補完 ・外れ値の処理 ・重複データの除去 |
| データ変換 | ・正規化:異なるスケールのデータを統一 ・標準化:平均0、分散1に調整 ・エンコーディング:カテゴリデータの数値変換 |
| 特徴量エンジニアリング | ・新しい特徴の作成 ・不要な特徴の削除 ・特徴量の選択と抽出 |
これらの前処理を適切におこなうことで、以下のような利点が得られます。
- モデルの学習効率の向上
- 予測精度の改善
- 過学習リスクの低減
- 計算コストの削減
データの品質管理と適切な前処理は、機械学習プロジェクトの成否を決める重要な要素です。時間と手間はかかりますが、この段階での丁寧な作業が、最終的なモデルの性能を大きく左右することを理解しておきましょう。
機械学習モデルの概念
機械学習モデルとは、データから規則性やパターンを学習し、新しいデータに対して予測や判断をおこなうための数理的な仕組みです。たとえば、住宅価格を予測する場合、面積や築年数などの情報(入力)から適切な価格(出力)を予測できるようになります。
モデルは以下のような基本構造を持っています。
- 入力層:データを受け取り、適切な形式に変換
- 計算部:さまざまな演算によってパターンを抽出・学習
- 出力層:予測結果や分類結果を提供
モデルの学習には、「パラメータ」と「ハイパーパラメータ」という2つの重要な要素があります。パラメータとは、モデルが学習の過程で自動的に調整する値(重みやバイアスなど)のことです。一方、ハイパーパラメータは、学習率や層の数など、学習前に人間が手動で設定する値を指します。
学習のプロセスは、以下のような段階で進められます。
- 目的関数の設定
- 予測と実際の値の差(誤差)を計算
- この誤差を最小化することが学習の目標
- 最適化の実行
- 勾配降下法などを用いてパラメータを調整
- 誤差が小さくなる方向に少しずつ更新
- 評価と改善
- 性能を定期的に測定
- 必要に応じて調整を繰り返す
このプロセスでとくに注意が必要なのが、「過学習」と「過少学習」という2つの問題です。
過学習は、モデルが訓練データに過度に適合してしまい、新しいデータに対する性能が低下する状態です。たとえば、生徒が問題集の答えを丸暗記してしまい、少し形式の異なる問題が解けなくなるようなケースです。これを防ぐには、以下のような対策が有効です。
- 正則化:モデルの複雑さに制限を加える
- データ増強:学習データを増やす
- モデルの単純化:必要以上に複雑な構造を避ける
一方、過少学習は、モデルの表現力が不足している状態です。基本的な概念が理解できていない生徒が、どんな問題も解けないような状況に似ています。これには以下の対策が効果的です。
- モデルの複雑化:層やノードを追加
- 特徴量の追加:より多くの情報を活用
- 学習時間の延長:十分な学習機会の確保
適切なモデル構築のためには、これらの問題のバランスを取りながら、定期的な評価と調整をおこなうことが重要です。とくに、交差検証などの手法を用いて、モデルが新しいデータにどの程度対応できるか(汎化性能)を適切に評価することが、実用的なモデルの開発には欠かせません。
このように、機械学習モデルの概念を理解し、適切に構築・調整することで、より精度の高い予測や分類が可能になります。ただし、完璧なモデルをつくることは難しく、常に改善の余地があることを認識しておくことも重要です。
機械学習の種類(主要な学習方法)

機械学習には、データの与え方と学習方法によって大きく3つの種類があります。それぞれ特徴的なアプローチと得意分野を持っており、解決したい課題に応じて適切な手法を選択することが重要です。
教師あり学習の特徴
教師あり学習は、もっとも一般的に利用される手法で、「正解」のあるデータを使って学習をおこないます。たとえば、多数の猫の画像に「これは猫です」というラベルを付けて学習させることで、新しい画像が与えられたときに「猫かどうか」を判断できるようになります。主要なタスクは以下の2つです。
| 分類(Classification) | データを定義済みのカテゴリに分類 例:メールのスパム判定(スパム/非スパム) 例:商品レビューの感情分析(ポジティブ/ネガティブ) |
| 回帰(Regression) | 連続的な数値を予測 例:翌月の売上予測 例:中古車の価格予測 |
これらのタスクを実現するため、以下のような代表的なアルゴリズムが使用されます。
- 線形回帰:数値予測の基本的な手法
- ロジスティック回帰:2値分類の代表的手法
- 決定木:ルールベースの予測モデル
- ランダムフォレスト:複数の決定木を組み合わせた手法
教師あり学習の最大の長所は、高い予測精度と結果の解釈のしやすさです。正解データを用いて学習するため、具体的な目標に対して直接的なアプローチが可能であり、予測の根拠も比較的明確です。とくにビジネスの現場では、売上予測や顧客の離反予測など、具体的な課題に対して即座に適用できる点が大きな利点となっています。また、モデルの性能評価が容易で、予測精度を定量的に測定できることも実用上の重要な利点です。
一方で、もっとも大きな短所は、大量の正解データ(ラベル付きデータ)が必要という点です。これらのデータを収集し、適切にラベル付けする作業には、多大な時間とコストがかかります。また、学習データに含まれていないような新しいパターンに対しては適切な予測ができない可能性があり、データの質や代表性が結果を大きく左右します。さらに、現実世界の問題では、必ずしも明確な正解が存在しない場合もあり、そのような状況では適用が難しいという制限もあります。
教師なし学習の特徴
教師なし学習は、正解のないデータからパターンや構造を自動的に発見する手法です。たとえば、購買データから似た傾向を持つ顧客グループを見つけ出すなど、データに潜む自然な関係性を明らかにすることができます。主要なタスクは以下の3つです。
| クラスタリング | 似た特徴を持つデータをグループ化 例:顧客セグメンテーション 例:商品のカテゴリ分類 |
| 次元削減 | データの本質的な特徴を保ちながら簡略化 例:複雑なデータの可視化 例:ノイズの除去 |
| 異常検知 | 通常とは異なるパターンの検出 例:不正取引の発見 例:製造ラインの品質管理 |
代表的なアルゴリズムには以下があります。
- K-means法(k平均法):シンプルで効果的なクラスタリング手法
- 主成分分析(PCA):データの次元を削減する標準的手法
- オートエンコーダ:非線形な次元削減が可能
教師なし学習の長所は、正解ラベルが不要であり、データから自然な構造やパターンを発見できる点です。人間が気づいていない新しい関係性や知見を見出すことができ、データの深い理解や洞察を得ることが可能です。とくに、ビッグデータ分析において、データの全体像を把握したり、隠れた特徴を発見したりする際に強力なツールとなります。また、データの収集コストが比較的低く、大量のデータを活用しやすいという利点もあります。
しかし、教師なし学習には、結果の評価が難しいという大きな短所があります。発見されたパターンや分類が実際に有用かどうかの判断には、ドメイン知識や専門家の解釈が必要となります。また、目的に応じた適切なアルゴリズムの選択や、パラメータの調整が難しく、計算コストが高くなる場合もあります。さらに、得られた結果を実際のビジネス施策に直接結びつけることが難しい場合もあり、実用化までには追加的な分析や解釈のステップが必要となることがあります。
強化学習の特徴
強化学習は、AIエージェントが試行錯誤を通じて最適な行動を学習する手法です。たとえば、ゲームAIが対戦を重ねることで戦略を改善していくように、行動の結果得られる報酬をもとに、よりよい選択を学んでいきます。主要な構成要素は以下の4つです。
| エージェント | ・学習と行動をおこなう主体 ・環境の状態を観察し、行動を選択 |
| 環境 | ・エージェントが活動する場 ・状態の変化と報酬を提供 |
| 行動 | ・エージェントが選択可能な操作 ・環境に影響を与える |
| 報酬 | ・行動の結果として得られる評価 ・学習の方向性を決定する指標 |
【代表的な応用例】
- ゲームAI(チェス、囲碁)
- ロボット制御
- 資源の最適配分
- 推薦システム
強化学習の長所は、複雑な問題に対して柔軟な適応が可能な点です。人間が明示的なルールを設計する必要がなく、試行錯誤を通じて最適な戦略を自ら発見できます。とくにゲームAIや制御システムなど、明確な目標があり、かつ試行錯誤が許される環境では、人間の能力を超える性能を実現することも可能です。また、環境の変化に応じて継続的に学習をおこない、性能を向上させ続けることができる点も大きな利点です。
一方で、強化学習の短所は、学習に時間がかかることと、適切な報酬設計が難しい点です。試行錯誤を繰り返す必要があるため、十分な性能を得るまでに多くの時間と計算リソースが必要となります。また、望ましい行動を引き出すための報酬設計には高度な専門知識が求められ、意図しない行動を学習してしまうリスクもあります。とくに実世界での応用では、学習過程での試行錯誤が危険を伴う可能性があるため、安全性の確保が重要な課題となっています。将来的には、シミュレーション環境での事前学習と実環境での調整を組み合わせるなど、より効率的で安全な学習手法の開発が期待されています。
機械学習の代表的なアルゴリズムとモデル

機械学習にはさまざまなアルゴリズムとモデルが存在し、それぞれに特徴的な仕組みと得意分野があります。ここでは、とくに重要な3つのアプローチについて、その仕組みと特徴をくわしく見ていきましょう。
ニューラルネットワークの基本構造
ニューラルネットワークは、人間の脳の神経回路を模倣した機械学習モデルです。複雑なパターンを段階的に学習できる柔軟な構造を持ち、とくに画像認識や自然言語処理などの分野で高い性能を発揮します。基本構造は3つの層から成り立っています。
- 入力層:データの入り口となる層で、画像のピクセル値や数値データなどを受け取ります
- 隠れ層:データの特徴を段階的に抽出する中間層で、複数重ねることができます
- 出力層:最終的な予測結果を出力する層で、タスクに応じて形式が変わります
各層には「ニューロン」と呼ばれる演算ユニットが配置されており、以下のような処理をおこないます。
- 入力の受け取り
- 前の層からの情報を重み付きで集約
- バイアス値を加えて調整
- 活性化関数による変換
- ReLU関数やシグモイド関数などで非線形変換
- モデルの表現力を向上させる重要な役割
学習は「順伝播」と「逆伝播」の2つのプロセスで進められます。
- 順伝播:入力から出力まで順に計算を進め、予測を生成
- 逆伝播:予測誤差をもとに、逆向きに重みを更新
この基本的な構造を発展させ、隠れ層を深く重ねたものが「ディープラーニング」です。層を深くすることで、より複雑なパターンの学習が可能になりますが、同時により多くのデータと計算リソースが必要となります。
決定木とランダムフォレストの特徴
決定木は、人間の意思決定プロセスに似た、直感的でわかりやすいモデルです。「Yes/No」の質問を順番におこない、最終的な判断に至る仕組みは、私たちの日常的な判断過程とよく似ています。
たとえば、「傘を持っていくべきか」という判断をする場合、以下のように質問を重ねながら結論に至ります。
- 天気予報は雨か?
- 雲は多いか?
- 気温は低いか?
決定木の大きな特徴は、この判断プロセスが視覚的に理解しやすい点です。しかし、単一の決定木には以下のような課題があります。
- 学習データに過度に適合しやすい
- わずかなデータの変化で結果が大きく変わる
- 複雑なパターンの学習が難しい
これらの課題を解決するために開発されたのが「ランダムフォレスト」です。多数の決定木を組み合わせることで、より安定した予測を実現します。それぞれの木に少しずつ異なるデータとパターンを学習させ、その予測を総合することで、単一の決定木よりも高い性能を実現できます。
サポートベクターマシン(SVM)の原理
サポートベクターマシン(SVM)は、データを分類する最適な境界を見つけることに特化したモデルです。とくに2つのクラスを分類する問題において、高い性能を発揮します。核となる考え方は以下のとおりです。
- マージンの最大化
- クラス間の境界をできるだけ広くとる
- もっとも近いデータ点(サポートベクター)との距離を最大化
- カーネルトリックの活用
- データを高次元空間に写像
- 非線形な分離を可能に
- 計算を効率的に処理
サポートベクターマシンの特徴は以下のとおりです。
| メリット | デメリット |
| 比較的少ないデータでも高い性能を発揮理論的な保証がある過学習しにくい | 大規模データの処理に時間がかかるパラメータの調整が必要結果の解釈が難しい |
これら3つのアプローチは、それぞれに特徴があり、問題の性質や要件に応じて使い分けることが重要です。
- ニューラルネットワーク:複雑なパターンの認識が必要な場合
- ランダムフォレスト:安定した予測と解釈可能性が求められる場合
- サポートベクターマシン:少ないデータで高い分類精度が必要な場合
実際の応用では、これらを組み合わせたり、ほかの手法と併用したりすることで、より効果的なソリューションを構築することも可能です。機械学習プロジェクトの成功には、これらの特徴を理解したうえで、適切なアルゴリズムを選択することが重要です。
機械学習の実践的な応用と活用事例

機械学習は、理論的な研究段階から実用段階へと急速に進化し、さまざまな産業で革新的な変化をもたらしています。ここでは、とくに注目される応用分野と、それらがもたらす具体的な価値について解説します。
画像認識と自然言語処理
画像認識と自然言語処理(NLP)は、機械学習のなかでもとくに注目される応用分野です。画像認識は、カメラやセンサーで捉えた画像データから物体を識別し、特徴を抽出する技術で、たとえば「畳み込みニューラルネットワーク(CNN)」の登場によって、画像データからの情報抽出が飛躍的に向上しました。CNNは画像内のピクセルの関連性を解析し、顔認識や医療画像の診断補助といった多様な分野で利用されています。
自然言語処理(NLP)では、文章や音声データを解析し、機械が人間の言語を理解・生成できるようにする技術が活用されています。最新の機械学習モデルを利用したアルゴリズムは、従来の手法と比べて大規模データの処理能力が飛躍的に向上しており、翻訳、チャットボット、感情分析などさまざまな応用が進んでいます。画像認識と自然言語処理は、医療・製造業・金融などの業界に革新をもたらし、自動化や効率化を支援すると同時に、新たなサービス提供にもつながっています。
予測分析と異常検知
予測分析と異常検知は、機械学習の応用で非常に重要な分野です。予測分析とは、過去のデータをもとに将来の出来事や状況を予測する技術で、需要予測や価格予測、リスク管理など幅広く使われています。需要予測では、過去の販売データや天候情報などを組み合わせて需要の変動を予測し、適切な在庫管理や生産計画を支援します。
一方、異常検知は、大量のデータから通常と異なるパターンや動作を検出し、異常事象を見つけ出す技術です。製造業では不良品の検出に用いられ、金融業界では取引データの分析を通じて不正検出に役立っています。これらの技術により、コスト削減やリスクの軽減が図れるだけでなく、品質向上や安全性確保にも貢献しています。異常検知の活用により、予防保全やセキュリティ対策も強化されており、ビジネスにおけるリスク管理の重要な手段として多くの企業が導入を進めています。
機械学習を活用したイノベーションの創出
機械学習は、既存のビジネスモデルに変革をもたらし、新しい価値を創出するイノベーションの原動力となっています。たとえば、顧客データを分析して個別のニーズに合った提案をおこなう「パーソナライズドマーケティング」は、機械学習の分析力を利用することで、より精度の高い顧客対応が可能です。
また、画像や音声認識の発展により、物流業での自動仕分け、音声アシスタントの進化など新たなサービスが生まれています。スタートアップ企業のなかには、機械学習技術を活用して、まったく新しいプロダクトやサービスを提供し、急速に市場で成功を収める事例も増えています。たとえば、医療分野での診断支援ツール開発や、自動運転システムの提供などがその一例です。今後も、データがさらなる価値を生む時代のなかで、機械学習を活用したイノベーションは、多様な分野で進化し続けるでしょう。
機械学習の導入における課題と対策

機械学習の導入はビジネスに多大な利便性をもたらす一方で、慎重な準備が求められます。とくに導入に際しては、以下の点に留意することが大切です
- 導入前段階での目的の明確化
- セキュリティ対策の徹底
- 必要なデータの収集
- データ整理の徹底
- 従業員の研修・資格取得支援の実施
これらの課題に対して適切に対策を講じることで、より実用的で持続可能な機械学習システムの導入が可能となります。以降でくわしく解説します。
導入前段階での目的の明確化
機械学習プロジェクトを成功に導くためには、導入前に明確な目的を設定することが重要です。目的があいまいなまま進めると、プロジェクトの進行中に軸がぶれ、結果的に期待していた成果を得られないリスクが高まります。
目的設定のステップとしては、まず解決したい課題を具体化し、その課題がビジネスに与える影響を見極めます。そのうえで、目標達成に向けた具体的な指標を設定し、関係者全体で共通の理解を持つことが大切です。
たとえば「売上向上」を目指す場合、顧客行動の分析や予測が必要であり、そのためにデータ収集が求められます。目的が不明確な場合、収集したデータや構築したモデルがビジネス目標に寄与しない恐れがあります。適切な目的設定が、機械学習導入の成功を左右する重要な要素となります。
セキュリティ対策の徹底
機械学習システムの導入には、セキュリティ対策が欠かせません。とくに個人情報や機密情報をとり扱う場合、データプライバシーを守るための対策が求められます。機械学習におけるセキュリティリスクには、データ漏洩、不正アクセス、モデルに対する攻撃などが含まれます。
こうしたリスクを軽減するためには、まずデータの保護と法的コンプライアンスを徹底することが重要です。具体的には、データの暗号化、アクセス制御、匿名化といった対策が有効です。
また、システム開発段階でのセキュリティテストを実施し、事前に脆弱性を洗い出すことも有効です。定期的なセキュリティ見直しをおこなうことで、データやモデルの安全性を保ちつつ、ビジネスに安心して機械学習を導入することが可能になります。
必要なデータの収集
機械学習において、必要なデータを正確に収集することは、モデルの精度と信頼性に直結します。データの種類としては、学習データ、検証データ、テストデータがあり、各段階で役割が異なります。学習データはモデルを訓練するため、検証データは性能の調整に、テストデータは最終的な評価に使用されます。
データの収集方法として、業務で得られる内部データのほか、公開データや外部機関からの取得も一般的です。また、データソースの選定に際しては、信頼性、鮮度、関連性を考慮し、収集したデータが適切かを判断する必要があります。さらに、個人情報保護法などの法的な配慮も求められ、倫理的観点からもデータ使用には慎重に扱いましょう。
データ整理の徹底
機械学習の性能を最大限に引き出すには、データ整理が重要なプロセスとなります。データクレンジングやデータ前処理といった整理作業を徹底することで、モデルの精度が大幅に向上します。データクレンジングでは、不足データや異常値の補完をおこない、前処理ではスケーリングや正規化、エンコーディングなどを通じてデータの質を向上させます。
効果的な整理手順としては、まずデータの現状を把握し、不備を特定してから、目的に合わせた処理を進めることが推奨されます。一般的な課題には、欠損値やデータのばらつきが挙げられ、これらに対応するためには具体的な対策を講じることが大切です。正確で整理されたデータは、精度の高いモデルの基盤となり、ビジネスでの活用価値を高めます。
従業員の研修・資格取得支援の実施
機械学習をビジネスに活用するためには、適切な知識やスキルを持った人材が必要です。そのため、従業員の研修や資格取得支援を実施することが重要です。効果的な研修プログラムでは、基礎知識から実践的なスキルまで段階的に習得できる内容が求められ、実例にもとづいたトレーニングやハンズオンでの実習が有効です。
また、主要な資格としては「G検定」や「E資格」などがあり、取得支援制度を整えることで従業員のモチベーションも高まります。これにより、導入初期段階からスムーズに機械学習プロジェクトを進められるだけでなく、社内に機械学習に精通した人材が育成され、長期的な成長が期待されます。研修を通じて社員全体の知識を底上げすることで、ビジネスの競争力強化につながるでしょう。
まとめ
機械学習をビジネスに導入するためには、目的設定、セキュリティ、データの質、従業員のスキルアップといった複数の課題を解決していくことが重要です。これらを1つずつ確実にクリアすることで、機械学習の効果を最大限に発揮し、ビジネスにおける競争力向上につながります。また、導入プロセスを体系的に理解し、計画的に取り組むことで、長期的に価値を生み出す機械学習環境を構築できます。以上の対策をもとに、適切な知識と準備を整え、成功に向けたプロジェクトを実現させましょう。
ディープラーニングで活用するならGPUクラウドサービスがおすすめ
ディープラーニングを活用する場合、GPUクラウドサービスが非常に効果的です。GPUクラウドサービスは、通常のCPUでは処理が遅くなる大量のデータや、複雑な計算を高速に処理するためのクラウド環境を提供します。
ディープラーニングは大量のデータ処理をおこなうため、GPUの並列処理能力が求められます。このサービスを利用すれば、設備投資を抑えつつ、高性能なGPUを利用できるため、開発コストの削減にもつながります。とくに学習モデルの訓練や実験においては、GPUクラウドサービスが速度とコスト面で大きな利点をもたらし、短期間で高品質な成果を得ることが可能です。
高火力 PHY

さくらインターネットの「高火力 PHY」は、NVIDIA H100 Tensor コアGPUを搭載したベアメタルサーバーを提供するサービスで、とくに大規模なデータ解析や複雑な機械学習モデルのトレーニングに向いています。このサービスは、AI研究や科学シミュレーション、さらにデータを駆使するプロジェクトを手掛けるプロフェッショナルや研究機関向けに設計されており、卓越した演算性能と柔軟な対応力を備えています。
また、ベアメタルサーバーであるため、ユーザーが独占的にGPUリソースを利用でき、最高レベルのパフォーマンスを発揮します。これにより、機械学習プロジェクトやディープラーニングの実験段階での利用に適しており、計算負荷の高いタスクやデータセットの処理が必要なシーンで大いに役立ちます。計算速度と精度を重視する高度なAIプロジェクトには、効率的かつパワフルな処理能力を提供するこのサービスが理想的です。
高火力 VRT

「高火力 VRT」は、さくらインターネットが提供するVM型GPUクラウドサービスです。
NVIDIA製のハイパフォーマンスGPUを仮想マシン上で提供し、クラウドの利便性をそのままにご利用いただけます。時間単位、日単位、月単位と柔軟な契約形態を採用しており、コスト効率を重視するプロジェクトにも最適です。
さらに、VM型の環境により、自由度が高く専用の開発環境を簡単に構築できる点も大きな特長です。機械学習やディープラーニング、リアルタイム性が求められるAIワークロードにも対応でき、短期間でGPU環境が必要な場合にも便利です。
とくに以下のような用途に適しています。
- チャットボットサービス(自然言語処理)
- 異常検知システム(動体検知・パターン検知)
- 対話型AIアバター(音声認識・音声合成・画像生成)
さらに、さくらのクラウドで提供されるストレージやネットワークなどのオプションとシームレスに連携可能。機械学習やディープラーニングなどの学習モデルを利用したアプリケーションを一元化できます。
高火力 DOK

「高火力 DOK」は、さくらインターネットが提供するコンテナ型GPUクラウドサービスで、NVIDIA V100やH100を利用できるため、画像生成AIや機械学習を始めるユーザーにも最適です。高火力 DOKは、Dockerイメージの利用により開発環境の設定が不要で、利用者はすぐにGPUを使ったタスク実行が可能です。
また、このサービスは従量課金制を採用しており、1秒単位での利用料金が設定されているため、コスト効率を重視するプロジェクトにも適しています。小規模な開発や一時的な利用、生成AIなどのスポットでの使用に最適で、AI学習を効率よく進めたい開発者にとって柔軟な選択肢を提供します。実行環境がコンテナ型であるため、異なるシステム間で同一の環境を再現することも簡単で、開発効率やコストパフォーマンスに優れたサービスです。




